| The C++Course provides a general introduction to programming in C++. It is based on A.B. Downey's book, How to Think Like a Computer Scientist. Click here for details. |

|
Home  Trees Array Implementation of Trees Trees Array Implementation of Trees |
||






|
  |
|
Array Implementation of Trees
What does it mean to "implement" a tree? So far we have only seen one implementation of a tree, a linked data structure similar to a linked list. But there are other structures we would like to identify as trees. Anything that can perform the basic set of tree operations should be recognized as a tree. So what are the tree operation? In other words, how do we define the Tree ADT?
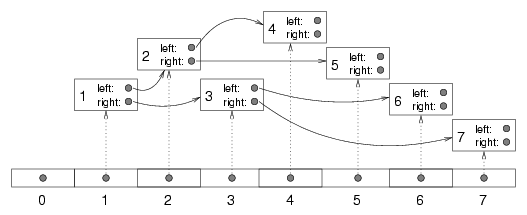
In the implementation we have seen, the empty tree is represented by the special value null. left and right are performed by accessing the instance variables of the node. We have not implemented parent yet (you might think about how to do it). There is another implementation of trees that uses arrays and indices instead of objects and references. To see how it works, we will start by looking at a hybrid implementation that uses both arrays and objects. This figure shows a tree like the ones we have been looking at, although it is laid out sideways, with the root at the left and the leaves on the right. At the bottom there is an array of references that refer to the objects in the trees.
In this tree the cargo of each node is the same as the array index of the node, but of course that is not true in general. You might notice that array index 1 refers to the root node and array index 0 is empty. The reason for that will become clear soon. So now we have a tree where each node has a unique index. Furthermore, the indices have been assigned to the nodes according to a deliberate pattern, in order to achieve the following results:
Using these formulas, we can implement left, right and parent just by doing arithmetic; we don't have to use the references at all! Since we don't use the references, we can get rid of them, which means that what used to be a tree node is now just cargo and nothing else. That means we can implement the tree as an array of cargo objects; we don't need tree nodes at all. Here's what one implementation looks like: public class Tree {Object[] array; public Tree () { array = new Object [128]; } No surprises so far. The instance variable is an array of Objects. The constructor initializes this array with an arbitrary initial size (we can always resize it later). To check whether a tree is empty, we check whether the root node is null. Again, the root node is located at index 1. public boolean empty () {return (array[1] == null); } The implementation of left, right and parent is just arithmetic: public int left (int i) { return 2*i; }public int right (int i) { return 2*i + 1; } public int parent (int i) { return i/2; } Only one problem remanins. The node "references" we have are not really references; they are integer indices. To access the cargo itself, we have to get or set an element of the array. For that kind of operation, it is often a good idea to provide methods that perform simple error checking before accessing the data structure. public Object getCargo (int i) {if (i < 0 || i >= array.length) return null; return array[i]; } public void setCargo (int i, Object obj) { if (i < 0 || i >= array.length) return; array[i] = obj; } Methods like this are often called accessor methods because they provide access to a data structure (the ability to get and set elements) without letting the client see the details of the implementation. Finally we are ready to build a tree. In another class (the client), we would write Tree tree = new Tree ();int root = 1; tree.setCargo (root, "cargo for root"); The constructor builds an empty tree. In this case we assume that the client knows that the index of the root is 1 although it would be preferable for the tree implementation to provide that information. Anyway, invoking setCargo puts the string "cargo for root" into the root node. To add children to the root node: tree.setCargo (tree.left (root), "cargo for left");tree.setCargo (tree.right (root), "cargo for right"); In the tree class we could provide a method that prints the contents of the tree in preorder. public void printPreorder (int i) {if (getNode (i) == null) return; System.out.println (getNode (i)); printPreorder (left (i)); printPreorder (right (i)); } We invoke this method from the client by passing the root as a parameter. tree.print (root);The output is cargo for rootcargo for left cargo for right This implementation provides the basic operations required to be a tree, but it leaves a lot to be desired. As I pointed out, we expect the client to have a lot of information about the implementation, and the interface the client sees, with indices and all, is not very pretty. Also, we have the usual problem with array implementations, which is that the initial size of the array is arbitrary and it might have to be resized. This last problem can be solved by replacing the array with a Vector.
|
||
| Home Trees Array Implementation of Trees |
|
|
Last Update: 2005-11-21