| VIAS Encyclopedia provides a collection of tables and definitions commonly needed in science and engineering. |

|
Home  Computer Science Huffman Encoding Computer Science Huffman Encoding |
|||
| See also: ASCII, ANSI and EBCDIC Encoding | |||






|
  |
||
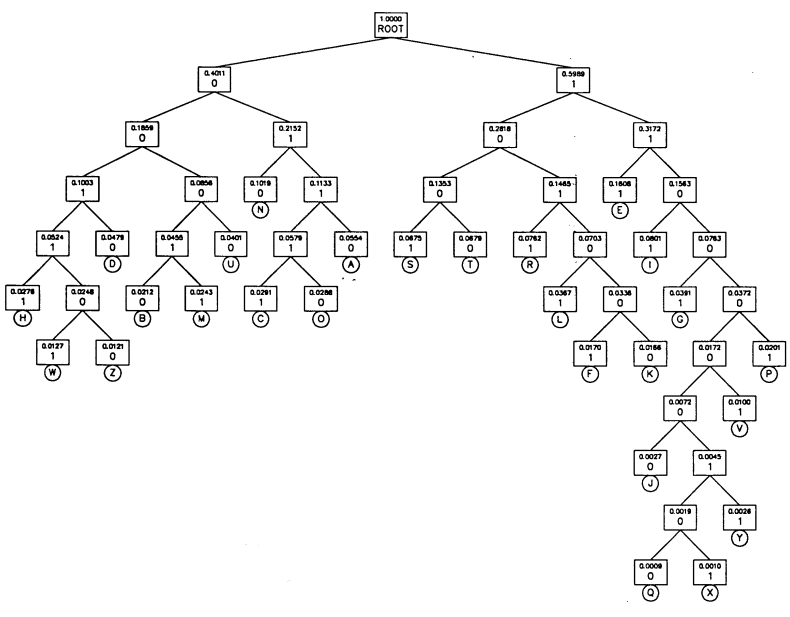
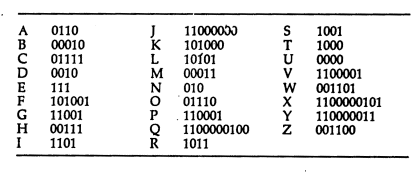
Huffman CodingHuffman coding, which has been developed by David A. Huffman in 1952, is an entropy encoding algorithm used for lossless data compression. The term refers to the use of a variable-length code table for encoding a source symbol (such as a character in a file) where the variable-length code table has been derived in a particular way based on the estimated probability of occurrence for each possible value of the source symbol. Huffman coding uses a specific method for choosing the representation for each symbol, resulting in a prefix-free code (that is, the bit string representing some particular symbol is never a prefix of the bit string representing any other symbol) that expresses the most common characters using shorter strings of bits than are used for less common source symbols. Huffman was able to design the most efficient compression method of this type: no other mapping of individual source symbols to unique strings of bits will produce a smaller average output size when the actual symbol frequencies agree with those used to create the code.
Assertions of the optimality of Huffman coding should be phrased carefully, because its optimality can sometimes accidentally be over-stated. For example, arithmetic coding ordinarily has better compression capability, because it does not require the use of an integer number of bits for encoding each source symbol. LZW coding can also often be more efficient, particularly when the input symbols are not independently distributed. The efficiency of Huffman coding also depends heavily on having a good estimate of the true probability of the value of each input symbol. Following is an example how to construct a Huffman code. Suppose you have to encode a text which contains only characters with the following frequencies of occurence:
Decoding a Huffman-encoded bit streamThe decoding procedure is deceptively simple. Starting with the first bit in the stream, one uses successive bits from the stream to determine whether to go left or right in the decoding tree. When we reach a leaf of the tree, we've decoded a character, so we place that character into the (uncompressed) output stream. The next bit in the input stream is the first bit of the next character.
|
|||
| Home Computer Science Huffman Encoding |
|
||

Last Update: 2005-10-04