Chunks
Chunks were designed to be easily tested and manipulated by computer
programs, easily detected by human eyes, and reasonably self-contained.
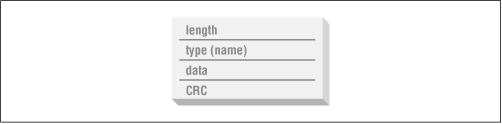
Every chunk has the same structure: a 4-byte length (in ``big-endian''
format, as with all integer values in PNG streams), a 4-byte chunk
type, between 0 and 2,147,483,647 bytes of chunk data, and a 4-byte
cyclic redundancy check value (CRC). This is diagrammed in
Figure 8-1.
The data field is straightforward; that's where the interesting bits (if
any) go; specific content will be discussed later, as each chunk is described.
The length field refers to the length of the
data field alone, not the chunk type or CRC. The CRC, on the other hand,
covers both the chunk-type field and the chunk data and is always present,
even when there is no chunk data. Note that the combination of length
fields and CRC values is already sufficient to check the basic integrity
of a PNG file! The only missing information--not including the contents
of the first 8 bytes in the file--is the exact algorithm (or
``polynomial'') used for the CRC. That turns out to be identical to the
CRC used by gzip and many popular archiving programs; it is described in
detail in Section 3.4 of the PNG Specification, Version 1.1,
available from http://www.libpng.org/pub/png/pngdocs.html.
The chunk type is possibly the most unusual feature. It is specified
as a sequence of binary values, which just happen to correspond to
the upper- and lowercase ASCII letters used on virtually every computer in
the Western, non-mainframe world. Since it is far more convenient (and
readable) to speak in terms of text characters than numerical sequences, the
remainder of this book will adopt the convention of referring to chunks by
their ASCII names. Programmers of EBCDIC-based computers should take note of
this and remember to use only the numerical values corresponding to the ASCII
characters.
Chunk types (or names) are usually mnemonic, as in the case of the IHDR
or image header chunk. In addition, however, each character in the
name encodes a single bit of information that shows up in the capitalization
of the character.[56]
Thus IHDR and iHDR are two completely different
chunk types, and a decoder that encounters an unrecognized chunk can
nevertheless infer useful things about it. From left to right, the four
extra bits are interpreted as follows:
-
The first character's case bit indicates whether the chunk is critical
(uppercase) or ancillary; a decoder that doesn't recognize the chunk type
can ignore it if it is ancillary, but it must warn the user that it cannot
correctly display the image if it encounters an unknown critical chunk.
The tEXt chunk, covered in Chapter 11, "PNG Options and Extensions", is
an example of an ancillary chunk. -
The second character indicates whether the chunk is public (uppercase)
or private. Public chunks are those defined in the specification or
registered as official, special-purpose types. But a company may wish
to encode its own, application-specific information in a PNG file, and
private chunks are one way to do that. The case bit of the third character is reserved for use by future versions
of the PNG specification. It must be uppercase for PNG 1.0 and 1.1 files,
but a decoder encountering an unknown chunk with a lowercase third character
should deal with it as with any other unknown chunk. The last character's case bit is intended for image editors rather than
simple viewers or other decoders. It indicates whether an editing program
encountering an unknown ancillary chunk[57]
can safely copy it into the new file (lowercase) or not (uppercase). If an
unknown chunk is marked unsafe to copy, then it depends on the image data in
some way. It must be omitted from the new image if any critical chunks
have been modified in any way, including the addition of new ones or the
reordering or deletion of existing ones. Note that if the program recognizes
the chunk, it may choose to modify it appropriately and then copy it to the new
file. Also note that unsafe-to-copy chunks may be copied to the new file if
only ancillary chunks have been modified--again, including addition, deletion,
and reordering--which implies that ancillary chunks cannot depend on other
ancillary chunks.
|

 PNG Basics
PNG Basics