 You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
| You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
|
Table of Contents  Multivariate Data Basic Knowledge Validation of Models Cross-Validation Multivariate Data Basic Knowledge Validation of Models Cross-Validation |
|
| See also: PRESS, validation of models |   |
While there are several different flavors of cross-validation, the fundamental idea stays the same: the model data is split into two mutally exclusive sets, a larger one (the 'training' set) and a smaller one (the 'test' set). The larger data set is used to set up the model, while the smaller data set is used to validate the model, i.e. the model is applied to the smaller data set and the results are compared to the expected values (as defined in the smaller data set). This process is then repeated with different subsets, until each object of the data set is used once for the test set.
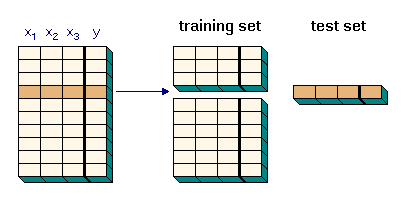
In order to measure the performance of the model, one should calculate
the PRESS value.
Last Update: 2006-Jän-17