 You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
| You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
|
Table of Contents  Univariate Data Measures of Location Mean Univariate Data Measures of Location Mean |
|
| See also: median, mode, standard deviation, comparing means, central limit theorem, confidence interval |   |
The mean is commonly called the average. It is calculated by adding
all the values and dividing the sum by the number of values. Let xi
represent the values of a variable X, with i = 1, 2, ..., n. The mean ![]() is then defined as:
is then defined as:
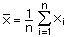
Note that there are also different definitions of the word mean (i.e. the geometric or the arithmetic mean). When the word "mean" is used without a modifier, it usually refers to the arithmetic mean as defined by the formula above.
Please note that there are different notations for the mean: the mean
of a population is denoted by m,
whereas the mean of the scores of a sample is denoted either by m, or by ![]() .
.
The mean is a good approximation of the central tendency for unimodal symmetric distributions, but can be misleading in skewed or multimodal distributions. Therefore, it can be useful to specify other additional measures of location for skewed distributions.
Hint 1: It can be shown that the sum of squared deviations of sample scores from their mean is lower than the squared deviations from any other value.
Hint 2: The mean is also often related to the accuracy
of an experiment. See the following![]() to get an impression of accuracy versus precision.
to get an impression of accuracy versus precision.
Last Update: 2006-Jän-17