 You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
| You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
|
Table of Contents  General Processing Steps Data Preprocessing Transformation of the Data Space General Processing Steps Data Preprocessing Transformation of the Data Space |
|
| See also: chemical example |   |
An extreme but comprehensible example will demonstrate the idea behind transformation of data space. Suppose you have two classes of objects which are described by three parameters x1, x2 and x3. Class 1 forms a cluster having a shape similar to an ellipsoid. The objects of class 2 are all located outside of the ellipsoid.
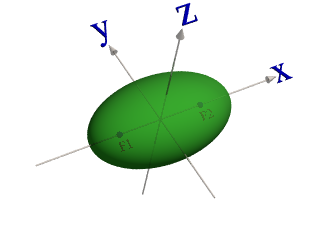
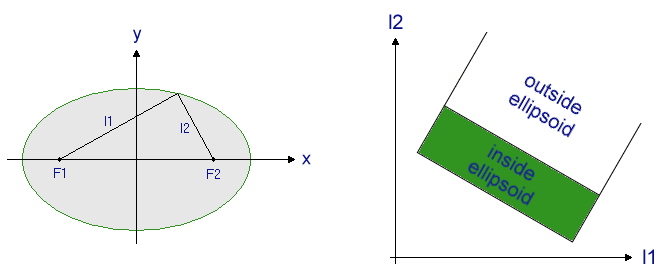
This simple example clearly shows that the transformation of the data
space can ease a given problem considerably. In fact, by knowing that cluster
1 forms an ellipsoid, and introducing some knowledge on analytical geometry,
we transformed the data space in such a way that (1) the number of necessary
variables is decreased and (2) the non-linear classification task
becomes a linear problem (which is easy to solve using well established
methods).
Last Update: 2006-Jän-18