 You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
| You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
|
Table of Contents  Multivariate Data Modeling Classification and Discrimination KNN classification Multivariate Data Modeling Classification and Discrimination KNN classification |
|
| See also: classification vs. calibration, discrimination and classification, k-Means Clusteranalyse |   |
K-Nearest Neighbor (KNN) classification is a very simple, yet powerful classification method. The key idea behind KNN classification is that similar observations belong to similar classes. Thus, one simply has to look for the class designators of a certain number of the nearest neighbors and weigh their class numbers to assign a class number to the unknown.
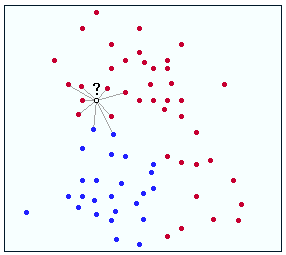
The weighing scheme of the class numbers is often a majority rule, but other schemes are conceivable. The number of the nearest neighbors, k, should be odd in order to avoid ties, and it should be kept small, since a large k tends to create misclassifications unless the individual classes are well-separated.
It can be shown that the performance of a KNN classifier is always
at least half of the best possible classifier for a given problem.
One of the major drawbacks of KNN classifiers is that the classifier needs
all available data. This may lead to considerable overhead, if the training
data set is large.
Last Update: 2006-Jän-17