 You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
| You are working with the text-only light edition of "H.Lohninger: Teach/Me Data Analysis, Springer-Verlag, Berlin-New York-Tokyo, 1999. ISBN 3-540-14743-8". Click here for further information.
|
Table of Contents  Multivariate Data Modeling MLR Estimation of New Observations Multivariate Data Modeling MLR Estimation of New Observations |
|
| See also: MLR, ANOVA |   |
When calculating the regression parameters ai of the general multiple linear regression equation

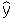 . While estimating the standard deviation of the parameters is quite simple, the estimation of the standard deviation of is rather complicated. The reason for this is that the distribution of depends on the particular set of ai. In general, the multivariate distribution function of can be rather complex.
. While estimating the standard deviation of the parameters is quite simple, the estimation of the standard deviation of is rather complicated. The reason for this is that the distribution of depends on the particular set of ai. In general, the multivariate distribution function of can be rather complex.
, the first being rather easy to implement, the second one is more demanding:
Rough Approximation: We can use the standard deviation s of the residuals to estimate the standard deviation of future values of y, i.e. . The interval of 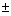 2s can be interpreted as a rough approximation to the accuracy of the model (that is, the accuracy with which the model will predict future values of y for particular values of xi). The calculation of s is easy and straightforward:
2s can be interpreted as a rough approximation to the accuracy of the model (that is, the accuracy with which the model will predict future values of y for particular values of xi). The calculation of s is easy and straightforward:
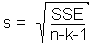
Exact Solution: The exact way to calculate the confidence interval of can be seen as an extension of the Working-Hotelling confidence band of simple regression. In the case of multiple linear regression this band becomes a k-dimensional volume. The estimated value falls within the (1-a) confidence interval:

Last Update: 2006-Jän-17